QueryNLQ
Ask your database questions in plain English.
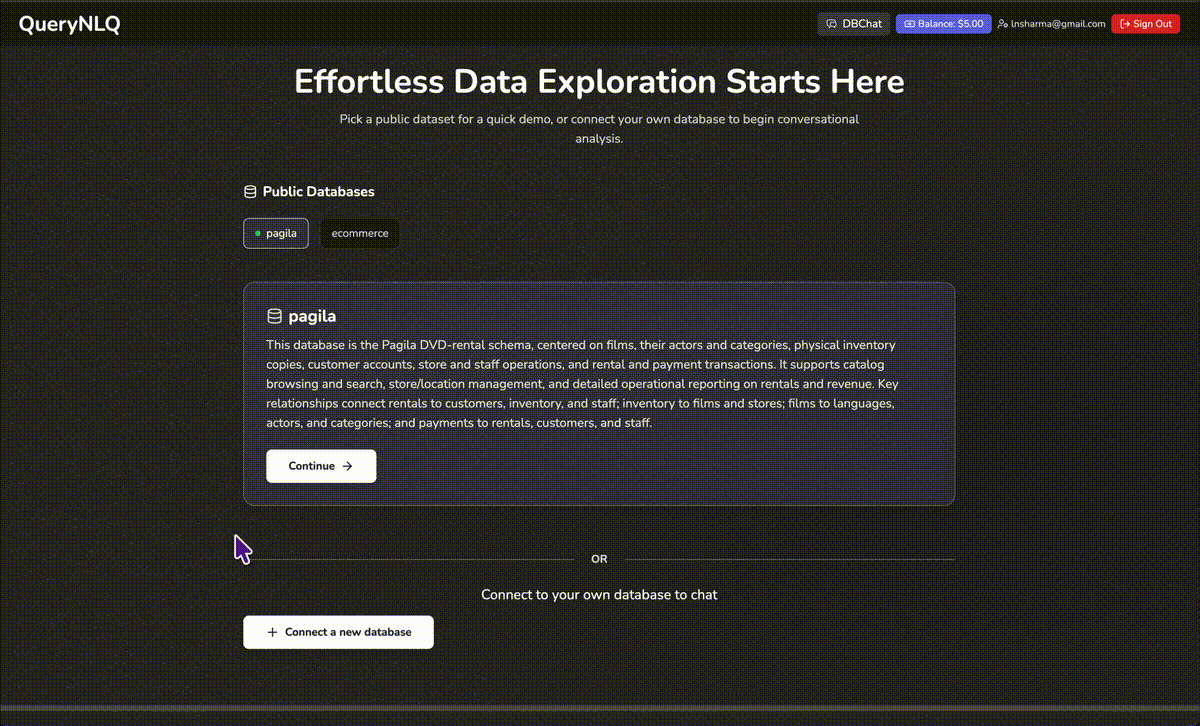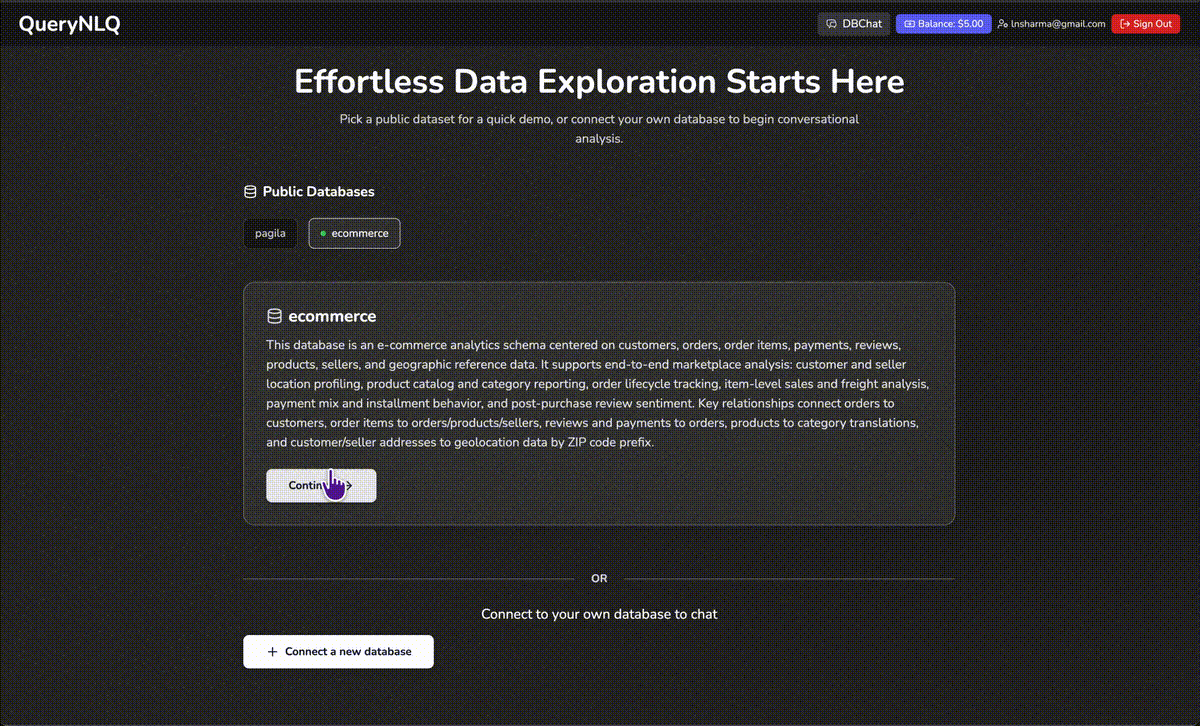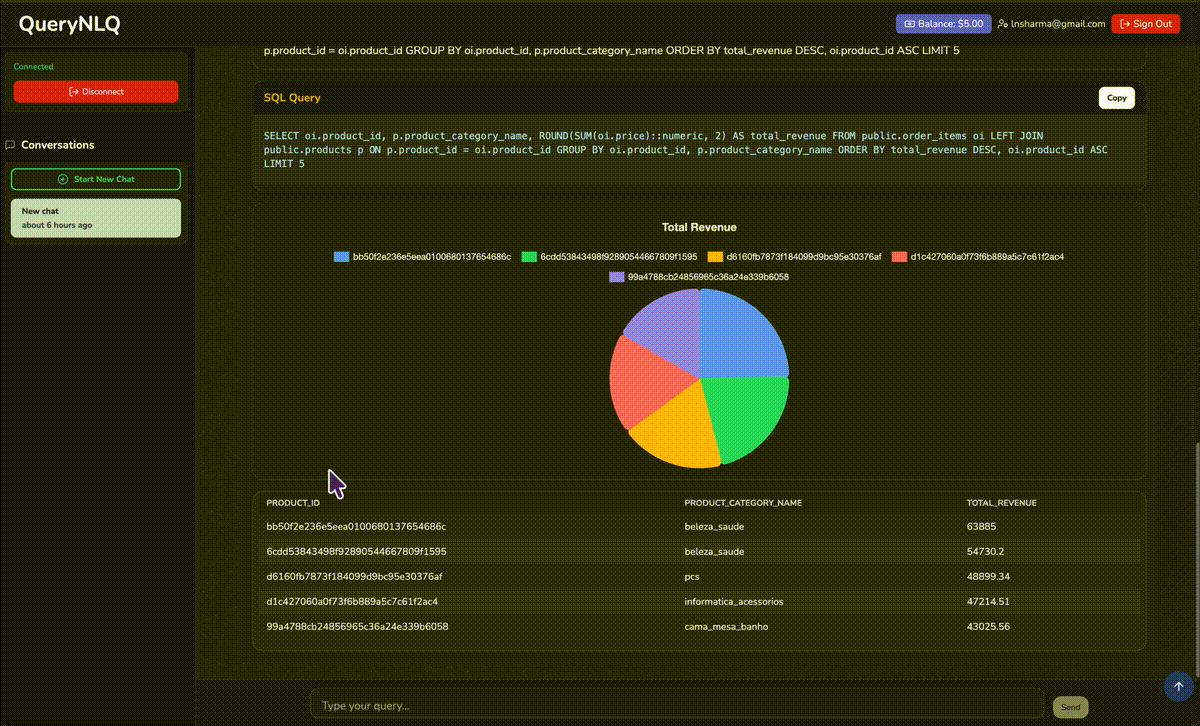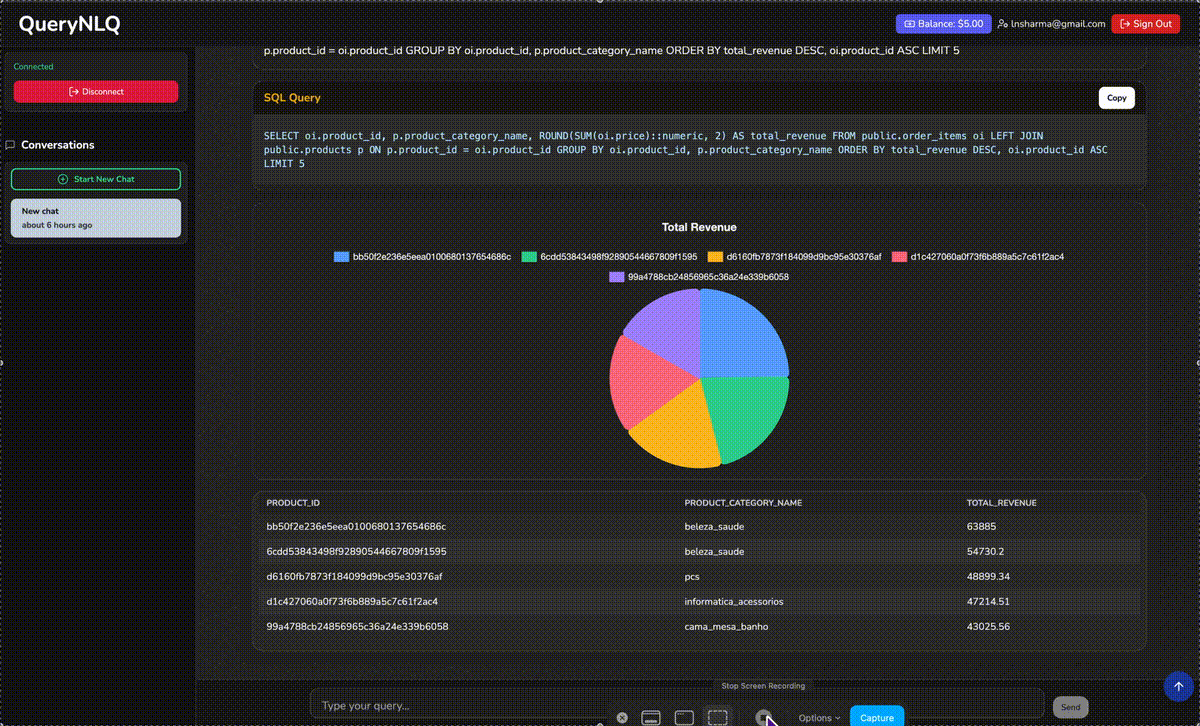
A 14-agent AI pipeline that turns natural language into production-grade SQL — against databases with 500+ tables. Not a ChatGPT wrapper. A self-correcting, type-safe agentic system with vector-based schema discovery, multi-stage verification, and real-time progress tracking.
See It Work
User asks:
“What were our top 10 customers by revenue last quarter?”
QueryNLQ processes through 14 specialized agents:
- Classifies intent → complex SQL query
- Plans approach → join orders + customers, aggregate revenue, filter by date range
- Searches 500+ table schema via Milvus → finds
orders,customers,invoicestables - Generates SQL with pruned schema context
- Verifies by executing in read-only transaction → 10 rows, no errors
- Reviews for logical correctness and performance
- Returns results + the SQL for full transparency
SELECT c.name, SUM(i.amount) as total_revenue
FROM orders o
JOIN customers c ON o.customer_id = c.id
JOIN invoices i ON o.id = i.order_id
WHERE o.order_date >= '2025-10-01' AND o.order_date < '2026-01-01'
GROUP BY c.name
ORDER BY total_revenue DESC
LIMIT 10;Time: under 3 seconds for simple queries. 15-30 seconds for complex multi-table analysis.
Follow-up: “Now filter that by the Asia region” → QueryNLQ maintains conversation context and modifies the query.
Complex analytical queries that work:
- “Run a cohort analysis — group customers by signup month and show retention over 6 months” → multi-CTE query with date bucketing, self-joins, and pivot logic
- “Analyze sentiment trends across support tickets by product category over the last quarter” → aggregation across multiple tables with text-based classification and time-series grouping
These aren’t cherry-picked demos. They represent the kind of multi-step analytical queries that typically require a data analyst writing custom SQL — handled end-to-end by the agent pipeline.
Results
- 90%+ query accuracy on production schemas with 500+ tables
- Sub-3s response for simple queries via the quick-pass path
- Self-correcting — verification + review loops catch and fix SQL errors before execution
- Zero unauthorized data access — read-only transactions, column-level permissions at the validation layer
- Real-time progress — users see which agent is working via WebSocket updates
The Problem
Business users drown in data they can’t access. At one MSME finance company, every ad-hoc question — “What’s our receivables aging by region?” or “Which customers haven’t ordered in 90 days?” — required a developer, a Slack thread, and a 2-day turnaround. Finance teams needed answers in minutes, not days.
The problem gets harder at enterprise scale. Databases with 500+ tables, cryptic column names like cust_acct_xref_id, and complex relationships across schemas. No single LLM prompt can hold 500 table DDLs. Single-prompt NL-to-SQL tools break at 20-30 tables.
Architecture: 14-Agent Query Pipeline
The query pipeline is orchestrated by Pydantic-Graph — a stateful directed graph where each node is a specialized Pydantic-AI agent with its own system prompt, output schema, and validation rules.
Entry: Intent Classification The UserInteraction agent classifies the query into six categories: general knowledge, simple SQL, complex SQL, data analysis, schema metadata, or needs clarification. A “quick pass” handles simple queries inline in under 3 seconds; complex queries are dispatched to Celery workers for async processing.
Planning: Approach → Execution → Tasks Three planning agents decompose complex queries. The ApproachPlanner generates a numbered strategy. The ExecutionPlanner converts it into concrete SQL steps. The TaskPlanner breaks it into discrete, executable tasks — each becomes an independent SQL generation cycle.
Discovery: Semantic Search → Schema Retrieval → Table Selection For each task, the SemanticSearch agent queries Milvus with an embedding of the enriched query. It returns the top-k most relevant tables from the 500+ table index. The SchemaRetrieval agent fetches their full JSON schemas. If there’s ambiguity, TableSelection asks the user to confirm.
Generation: SQL → Verification → Review (self-correcting loop) The SQLGeneration agent produces SQL using the pruned schema, task instructions, and conversation history. SQLVerification executes it in a read-only transaction to check for errors and anomalies. SQLReviewer validates logical correctness and performance. If either finds issues, the query loops back to SQLGeneration with specific feedback — a self-correcting cycle that runs until the SQL passes all checks.
Safety: Error Handling & Loop Detection An ErrorHandler agent analyzes failures and routes to recovery. A LoopDetectionManager tracks per-agent visit counts — if an agent is visited too many times, the system breaks the loop and asks the user to rephrase. No infinite cycles.
Architecture: Schema Embedding Pipeline
Before a single query can be answered, the database must be indexed. This is the pipeline that makes QueryNLQ work at enterprise scale.
1. Extract — SQLAlchemy’s inspector extracts every table, column, type, constraint, index, and foreign key. A ThreadPoolExecutor (10 workers) processes tables in parallel. Row counts and sample values are collected for context.
2. Describe — A Pydantic-AI agent generates natural-language descriptions of every table and column — using column names, types, sample values, and relationships as context. Runs as Celery batch tasks with dynamic sizing: the system monitors active tasks and adjusts batch size to stay within concurrent LLM call limits. Memory monitored per-batch to prevent OOM.
3. Enrich — Each table and column gets an “enriched embedding text” — a structured summary including description, expanded types, sample values, relationships, indexes, purpose, and synonyms. This enriched text is what gets embedded, not just the raw column name.
4. Embed — Azure OpenAI’s text-embedding-3-large (3072 dimensions) generates vectors with token-aware batching. Embeddings are unit-normalized for inner product similarity.
5. Store — Two Milvus collections (tables + columns) with HNSW indexing. When the schema changes, the system diffs live vs. stored, deletes orphans, and upserts new entries — no full re-index needed.
Key Technical Decisions
-
Pydantic-Graph, not LangGraph — Type-safe node definitions with Pydantic output schemas enforced at every stage. Each agent has explicit input/output contracts, not free-form string passing.
-
14 specialized agents, not one mega-prompt — A single prompt with the full schema and all instructions hits context limits and produces unreliable SQL. Specialized agents with focused prompts and constrained outputs are more reliable and auditable.
-
Milvus vector search, not prompt stuffing — Stuffing 500 table DDLs into a prompt is impossible. Semantic search over embedded schema descriptions returns the 10 most relevant tables per query, keeping the SQL generation prompt focused.
-
sqlglot + SQLAlchemy for validation, not LLM self-check — SQL is validated by parsing (sqlglot), executing in a read-only transaction (SQLAlchemy), and checking results — not by asking the LLM “is this correct?”
-
Celery + Redis for async — Complex queries take 15-30 seconds across multiple agent hops. Celery workers process asynchronously while WebSocket pushes real-time progress to the UI.
-
Quick pass for simple queries — UserInteraction runs inline with a 3-second timeout. Simple classification and general questions are handled without Celery overhead.
Tech Stack
- Agent Framework: Pydantic-AI 1.60 — structured output schemas, output validators, multi-provider support
- Orchestration: Pydantic-Graph 1.60 — stateful directed graph with typed state and node routing
- LLM Providers: Azure OpenAI (GPT-5.4), Anthropic Claude, Google Gemini, Groq
- Vector Database: Milvus 2.5 — HNSW indexing, 3072-dim embeddings, two collections (tables + columns)
- Embeddings: Azure OpenAI text-embedding-3-large
- SQL Parsing: sqlglot 26 + SQLAlchemy 2.0
- Backend: Django 5.2 + django-ninja (FastAPI-style routing)
- Async: Celery 5.4 + Redis + Django Channels (WebSocket)
- Database: PostgreSQL
Visual Architecture
How the 14 agents collaborate — and how databases are indexed for semantic search.
Query Pipeline Flow
User Query
Natural language input
User Interaction Agent
Intent classification · Clarification · Quick pass (3s)
Approach Planner
Strategy generation
Execution Planner
Concrete SQL steps
Task Planner
Discrete task queue
Semantic Search
Milvus vector lookup
Schema Retrieval
JSON schema pruning
Table Selection
Disambiguation
SQL Generation
Pydantic-AI agent
SQL Verification
Execute in transaction
SQL Reviewer
Logic + performance
SQL Execution
Results returned · Max 1000 rows · WebSocket push
Error Handler + Loop Detection
Recovery routing · Graceful degradation · Per-agent visit thresholds
Schema Embedding Pipeline
How QueryNLQ indexes a 500+ table database for semantic search — before a single query is answered.
Want to build something like this?
Let's talk about your project. No commitment, no slides — just a conversation about what's possible.
Get in Touch